Abfragen an eine Tabelle
|
Tabelle vollständig auswählen |
SELECT * FROM meine_Tabelle
|
Wählt alle Datensätze aus der Tabelle meine_Tabelle aus.
|
| Spalten auswählen |
SELECT Spalte1, Spalte2
FROM meine_Tabelle
|
Wählt die Spalten Spalte1 und Spalte2 aller Datensätze aus der Tabelle meine_Tabelle aus.
|
| eindeutige Werte |
SELECT DISTINCT Spalte1
FROM meine_Tabelle
|
Wählt alle verschiedenen Werte innerhalb von Spalte1 aus.
|
| sortieren aufsteigend |
SELECT * FROM meine_Tabelle
ORDER BY nachname ASC
|
Wählt alle Datensätze aus der Tabelle meine_Tabelle aus und sortiert nach dem Feld Nachname aufsteigend. Der Parameter ASC sortiert aufsteigend.
|
| sortieren absteigend |
SELECT * FROM meine_Tabelle
ORDER BY datum DESC
|
Wählt alle Datensätze aus der Tabelle meine_Tabelle aus und sortiert nach dem Feld Datum absteigend. Der Parameter DESC sortiert absteigend.
|
| Datensätze auswählen I |
SELECT * FROM meine_Tabelle
WHERE IDNummer > 32
|
Wählt alle Datensätze aus der Tabelle meine_Tabelle aus, deren Feld IDNummer grösser als 32 ist. Die Vergleichs-Operatoren sind: =, <, >, <=, >= und <> (ungleich)
|
| Datensätze auswählen II |
SELECT * FROM meine_Tabelle
WHERE Spalte1 LIKE '%text%'
|
Wählt alle Datensätze aus der Tabelle meine_Tabelle aus, deren Feld Spalte1 die Zeichenkette 'text' enthält. Dabei ist % ein Platzhalter für ein oder mehrere Zeichen.
|
| Datensatz einfügen |
INSERT INTO meine_Tabelle (feld_eins, feld_zwei)
VALUES (31, 'Müller')
|
Fügt der Tabelle einen neuen Datensatz hinzu. An die Felder feld_eins und feld_zwei wird je ein Wert übergeben.
|
| Datensatz ändern |
UPDATE meine_Tabelle
SET feld_eins = 34, feld_zwei = 'Arnold'
WHERE IDNummer = 12
|
Beim Datenatz mit IDNummer = 12 werden in den Feldern feld_eins und feld_zwei neue Werte eingetragen.
|
| Datensatz löschen |
DELETE FROM meine_Tabelle
WHERE IDNummer = 12
|
In der Tabelle meine_Tabelle wird der Datenatz mit IDNummer = 12 gelöscht.
|
Abfragen an mehrere Tabellen
|
| Kreuztabelle |
SELECT * FROM Tabelle1, Tabelle2
|
Kreuzprodukt (kartesisches Produkt) zweier Tabellen. Jeder Datensatz wird mit jedem verknüpft. Dies kann zu sinnlosen Datensätzen führen. Die Anwendung in nur in speziellen Fällen sinnvoll.
|
| Join von zwei Tabellen |
SELECT * FROM Tabelle1, Tabelle2
WHERE Tabelle2.Fremdschlüssel = Tabelle1.Primärschlüssel
|
Vereinigung (Join) zweier Tabelllen. Dabei hat die Tabelle2 einen Fremdschlüssel, der auf den Primärschlüssel der Tabelle1 verweist.
|
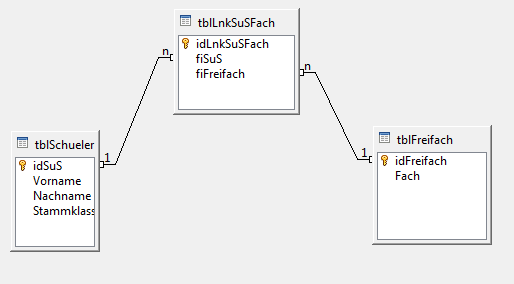
| n:n-Beziehung |
SELECT Fach, Vorname, Nachname, Stammklasse FROM tblLnkSuSFach, tblSchueler, tblFreifach WHERE tblLnkSuSFach.fiSuS = tblSchueler.idSuS AND tblLnkSuSFach.fiFreifach = tblFreifach.idFreifach
|
Abfrage einer n:n Beziehung über drei Tabellen hinweg. Das Dantenbankmodell sieht wie folgt aus:
|
Aggregatfunktionen
|
| Summe (SUM) |
SELECT Spalte1, SUM(Spalte2) AS Anzahl
FROM Tabelle1 GROUP BY Spalte1
|
Gruppiert die Datensätze nach der Spalte1 (jeder Wert wird nur einmal ausgegeben) und die Summe der Spalte2 wird ermittelt. Die Summe wird dank AS mit dem Spaltennamen Anzahl versehen.
Die Aggregatfunktionen sind:- COUNT (Anzahl)
- SUM (Summe)
- MIN (Minimum)
- MAX (Maximum)
- AVG (Average = Durchschnitt)
|